A mesterséges neurális hálózatok fogalma az 1980-as, 90-es években már nem először járta be a világot – kutatók ezrei és az ipar is óriási reményeket fűzött hozzá. Idővel azonban az akkor kidolgozott eljárás elérte korlátait és jelentősebb eredmények hiányában a gépi tanulás szakértői más, abban az időben hatékonyabb módszerek felé fordultak. Ugorjunk előre az időben! Ma a kutatók a mély tanuláson alapuló neurális hálózatok segítségével a legtöbb tudományterületen minden korábbinál jobb, pontosabb eredményt érnek el. De mi is az az újdonság, aminek köszönhetően a neurális hálózat felülkerekedett korábbi korlátain? És mire képesek napjaink legfejlettebb mély tanuló rendszerei?

A mesterséges mély neuronháló bemeneti rétegét számos rejtett, végül pedig a kimeneti réteg követi. Minden rejtett rétegben meghatározott számú elemi neuron található, amelyek az előző rétegbeli összes neuron kimenetének súlyozott összegét állítják elő, majd ezt minden neuron egy úgynevezett aktivációs (nemlineáris) függvénybe táplálja. Sokszor hivatkoznak az elemi neuron és az élő idegsejt közötti analógiára: az idegsejtben található dendritek megfelelője a neuron bemenetei, a sejttesté az összegzés, az axonoké pedig az aktivációs függvény. Bár tagadhatatlan a két elemi egység közötti párhuzam, fontos kiemelni, hogy az élő idegrendszer működése már mai tudásunk alapján is sokkal összetettebb ennél.
A neuronháló felügyelt tanítása során be- és kimenetpárokat táplálunk a hálózatba (például fotók képpontjai a bemenetek, a kimenetek pedig valószínűségeket tartalmaznak arról, hogy mi látható a képeken). A kimeneten mért hiba alapján úgy módosítjuk a neuronokat összekötő súlyokat a hibavisszaterjesztés-algoritmus segítségével, hogy a kimeneti hiba egyre csökkenjen. A tanítás végén a tanító adatokhoz hangolt neuronokat összekötő súlyokban lesz a neuronháló tudása.
Neuronhálók tele
A neuronhálók sikerének az 1990-es években többek között az szabott határt, hogy nem tudták hatékonyan tanítani a több rejtett réteggel rendelkező neuronhálókat. A korábbi nagy reményeket a kiábrándultság, a „neuronhálók tele” váltotta fel. Három dolog együttes teljesülésére volt szükség ahhoz, hogy a tudományterület napjainkra újból lendületbe jöjjön: új tudományos eredményekre, nagyobb számítási teljesítményre és több adatra.

Az elemi neuron (fent) és biológiai megfelelője, az idegsejt (lent, módosítva freepik.com alapján)
Már a „neuronhálók tele” alatt is igen fontos eredmények születtek. Ekkor dolgozta ki Yann LeCun, a New York-i egyetem professzora a Bell Laboratóriumban a ma legnagyobb kép- és beszédfelismerési pontosságot adó mély konvolúciós neuronháló alapját jelentő LeNet-et. Szintén ekkor alkották meg egy neves svájci mesterségesintelligencia-kutatólaboratóriumban a mai mély tanulás alapú természetes nyelvfeldolgozás és idősor modellezés egyik leghatékonyabb módszerét, a Long Short-Term Memory (LSTM) hálózatok elméletét. A „tél végét” talán 2006-ban Geoffry E. Hinton, a Torontói Egyetem professzor emeritusának a Science-ben megjelent eredménye jelentette, melyben a több rejtett rétegből álló mély hálózatok tanítására minden korábbinál hatékonyabb módszert mutatott be. Részben az ő nevéhez köthető maga a mély tanulás fogalma is, mely szerint mély tanuló rendszereknek nevezzük az olyan gépi tanuló algoritmusok strukturált összességét, mely rétegei a bemeneti adatok magasabb szintű absztrakcióinak kinyerésével hatékonyan képesek egy tetszőleges folyamatot modellezni. A gyakorlatban a mély tanulás jellemzően a mély neuronhálók tanítását jelenti.
A második szükséges feltétel a számítási teljesítmény drasztikus növekedése volt. A neuronhálók tanítása során nagyszámú mátrixműveletet hajtunk végre, hasonlóan a számítógépes grafikához. Mivel az utóbbi évtizedek óta használt kifejezetten ilyen műveletekre optimalizált grafikus kártyákat (Graphical Processing Unit, GPU), adott volt mély tanulásban történő alkalmazásuk. Napjaink GPU-i 32 bit-en már akár 6600 gigaflopra (lebegőpontos műveletre másodpercenként) is képesek. Összehasonlításképp egy mai erősebb asztali számítógép teljesítménye 50–100 gigaflop között van. A mély tanulás fejlődését tovább segítette, hogy 2007-ben megjelent a GPU-k hatékony programozását lehetővé tevő CUDA, majd 2009-ben az OpenCL programozási nyelv.
Harmadrészt pedig a nagy mennyiségű adat, azaz a big data az, amire a mély neuronhálóknak szüksége volt. Ma ugyanis már nem ritka dolog, hogy több terabájtnyi adattal tanítjuk a mély hálózatokat. Ez az adatmennyiség az 1990-es években mind a számítási-, mind pedig a tárolókapacitás miatt elképzelhetetlen volt.
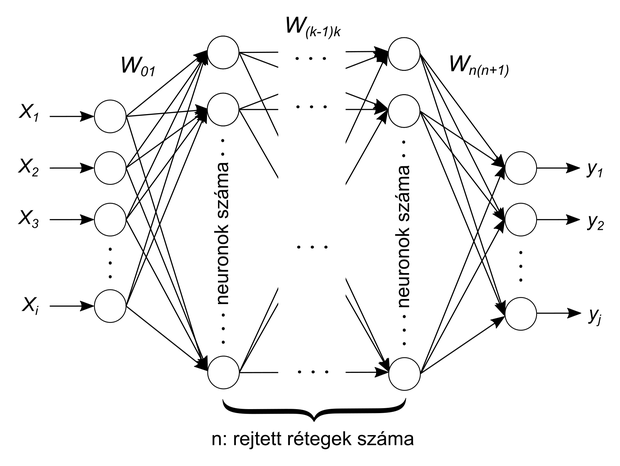
Elemi neuronokból felépített többrétegű előrecsatolt mély neurális hálózat, ahol Xi a bemeneteket, yj a kimeneteket, W pedig két réteg közötti súlyokat jelöli
A fenti feltételek teljesülésével 2006–2007-től a neuronhálók újból nagy figyelmet kaptak, de a mély tanuló rendszerek igazán csak az elmúlt pár évben terjedtek el. Azóta számos egyetem és kutatólaboratórium adott ki nyílt forráskódú mély tanuló keretrendszert, amely eszközök nagyban segítik a szakemberek munkáját. Napjaink mély neurális hálózatai számos rétegtípusból épülhetnek fel, ezek közül jelenleg talán a három legfontosabb az előrecsatolt, a konvolúciós és a visszacsatolt egységek.
Architektúrák
Az előrecsatolt mély neurális hálózat felépítése megegyezik a korai többrétegű neuronhálóéval, de ennek teljesítményét sokszor javítják új algoritmu-sokkal (például újtípusú inicializálás és aktivációs függvény). Az előrecsatolt háló alkalmas osztályozási és regressziós problémák megoldására.
A konvolúciós mély neurális hálózatot leggyakrabban az adatok magasabb szintű absztrakcióinak a kinyerésére használjuk. Korábban a tanuló algoritmusok számára az adatokat „jobban tanulható” formára kellett alakítani, melyhez sokszor egy-egy szakterület átfogó ismeretére volt szükség (például onkológiai ismeretek). A konvolúciós háló ezzel szemben az adatokból tanulja meg, hogy mi a „legmegfelelőbb forma” és egyben ehhez igazítja a bemeneteket. A kétdimenziós konvolúciót hatékonyan alkalmazzák például a kép- és beszédfelismerésben, a szignálazonosításban. A háromdimenziós konvolúció alapú videótartalom-feldolgozás szintén aktív kutatási terült.
Idősor elemzés és előrejelzés céljából visszacsatolt mély neurális hálózatot, ezen belül napjainkban leginkább a korábban már említett LSTM-struktúrát alkalmazunk. Az LSTM – a klasszikus visszacsatolt hálókhoz viszonyítva – többek között képes az idősorok távoli összefüggéseinek feltérképezésére és modellezésére. Mindemellett az LSTM a leggyakrabban használt architektúra a természetes nyelvfeldolgozásban, szövegelemzésben és a nyelvi modellezésben is.
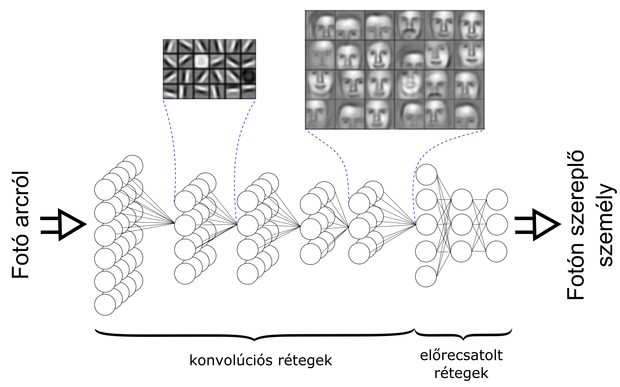
Példa a mély konvolúciós hálózat által tanult jellemzőkre arcfelismerés esetén. Sikeres tanítás végeztével az alacsonyabb konvolúciós rétegek súlyai éldetekció-, a magasabb rétegek súlyai arcszerű jellemzőket tartalmaznak. Az előrecsatolt rétegek az osztályozást végzik. (Forrás: nvidia.com alapján módosítva.)
A fenti három réteg – és egyben mély háló típus – együttes alkalmazásával először a tanítóadatoknak egy magasabb szintű absztrakcióját nyerjük ki (konvolúciós réteg), majd idősor esetén ennek időbeliségét modellezzük (visszacsatolt réteg), ezt követően pedig osztályokba soroljuk, vagy egy jövőbeli időpillanatot jósolunk (előrecsatolt réteg).
Szövegolvasás
A Budapesti Műszaki és Gazdaságtudományi Egyetem Távközlési és Médiainformatikai Tanszékén aktív kutatás folyik mély neurális hálózatok területén. A mély tanulás alapkutatásán túl a hang- és beszédtechnológiai, továbbá az ember-gép kapcsolatot segítő gyakorlati alkalmazásával foglalkozunk.
A gépi szövegfelolvasó rendszer segítségével a szöveget a számítógép természetes, emberi hangon olvassa fel. Hogy a mély neurális hálózatot szövegfelolvasásra tanítsuk, nagyméretű (akár több tíz órányi) beszédadatbázisra van szükség, melyben a stúdióminőségű hangfelvételek mellett szerepel a szöveg fonetikus átirata is. A mély háló bemenetét képezi egyrészt a fonetikus átirat numerikus reprezentációja beszédhangonként az aktuális, továbbá az előző és következő két hang megjelölésével. Másrészt a bemeneten szerepel az aktuális hang szótag-, szó-, mondatrész- és mondatbeli pozíciója, és számos, a beszédhangot leíró egyéb jellemző (például hangsúlyos-e a hanghoz tartozó szótag). Ahogyan a telefon is paraméterekre bontja a hangunkat és ezen paramétereket küldi át a telefonvonal túlsó végére, amiből újból beszédhangot generál, úgy bontjuk mi is spektrális (hangszín), gerjesztési (hangmagasság, zöngésség) és időzítési (beszédritmus) paraméterekre a hullámformát – és adjuk a tanítás során a mély háló kimenetére. A tanító adatbázis méretének és a mély háló paramétereinek függvényében egy hálózat tanítása napjaink csúcsteljesítményű GPU-in akár több hétig is tarthat. Ráadásul az optimális hálózattopológia és paraméterbeállítás meghatározására javarészt ma még empirikus módszerek állnak csak rendelkezésre, így a legjobb hangminőséghez több száz tanítást le kell futtatnunk. Sikeres tanítást követően a mély neurális hálózat súlyait adatbázisban tároljuk.
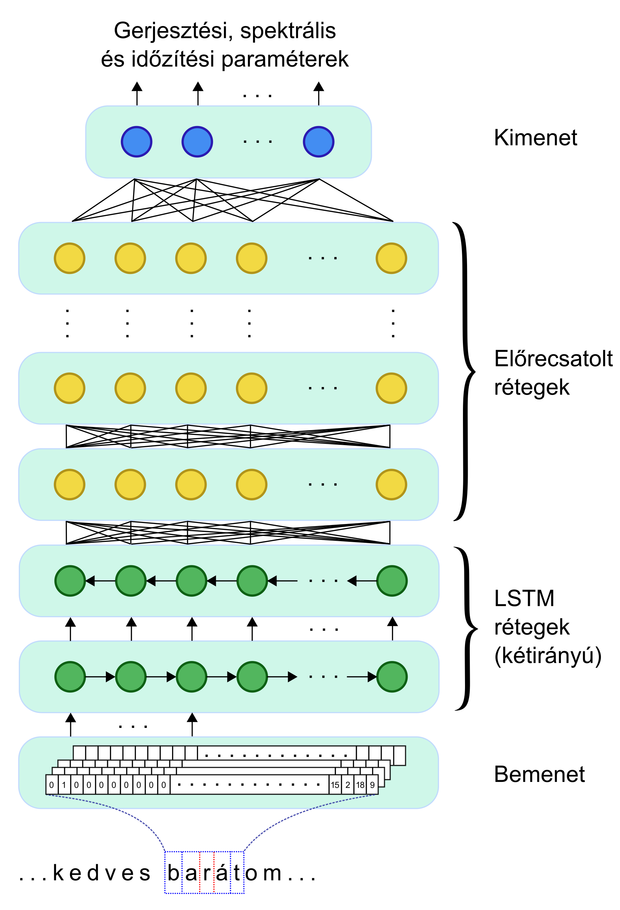
Általános mély neuronháló alapú gépi szövegfelolvasó blokkvázlata. A fonetikus átiratot („…kedves barátom…”) numerikus bemenetté alakítjuk, majd LSTM- és előrecsatolt rétegekkel tanítjuk meg a gépi beszéd előállításához szükséges gerjesztési, spektrális és időzítési paramétereket.
Szövegfelolvasás során ezeket a súlyokat töltjük be és – a korábbiaknak megfelelően – immár a tanító adatbázisban nem szereplő szöveget adunk a bemenetre, mely szöveghez a beszédparamétereket a hálózat becsüli meg. Végső lépésként a becsült paraméterekből a telefonban használt algoritmushoz hasonló beszédkódoló eljárással állítjuk elő a gépi beszédet. A gépi szövegfelolvasáshoz a mély háló – a nemzetközi szakirodalmat követve – jellemzően két réteg LSTM-ből és 3-8 előrecsatolt rétegből épül fel. A súlyozott összeköttetések száma a konkrét architektúrától függően 10–100 millió között mozog, ez adja a mély neurális hálózat alapú szövegfelolvasó tudását. Így ma már általános kijelentő mondatok esetén a természetes beszéddel összetéveszthető minőséget is el lehet érni. Mindazonáltal a tudományterület még számos megoldandó problémával áll szemben – ilyen például a hosszabb szövegek változatos módon történő felolvasása, vagy a rövid és kérdő mondatok modellezése. Szintén aktív kutatási terület a szabályalapú fonetikus átírás kiváltása LSTM alapú hálózatokkal, illetve a klasszikus beszédkódoló helyettesítése konvolúciós és dekonvolúciós rétegekkel.
A mély neurális hálózatok térhódítása szükségszerűen tovább folyik, hiszen az adatok mennyisége és a számítási kapacitás is egyre növekszik. Jelenleg még nem látni, hogy mikor érjük el a technológia határait, amit a cégóriások hozzáállása is tükröz. Elon Musk (PayPal, SpaceX, Tesla Motors) például számos további befektetővel 2015 decemberében 1 milliárd dollár kezdőtőkével elindította az OpenAI nonprofit kutatócsoportot, melynek célja új típusú mély tanuló megoldások létrehozása az emberiség szolgálatában.
TÓTH BÁLINT PÁL
KISLEXIKON
(Mesterséges) neurális hálózat: az emberi idegrendszer alapján ihletett gépi tanuló architektúra, matematikai modell. Adatok alapján képes a mögöttes folyamat, tartalom modellezésére, felismerésére, előrejelzésére. Alkalmas például képfelismerésre, beszédfelismerésre, idősor előrejelzésre.
Mély neurális hálózat: a bemeneti és kimeneti réteg között több rejtett rétegből álló neurális hálózat.
Mély tanulás (deep learning): gépi tanuló algoritmusok strukturált összesége, melynek rétegei a bemeneti adatok magasabb szintű absztrakcióinak kinyerésével hatékonyan képesek tetszőleges folyamatot modellezni
Előrecsatolt/konvolúciós/visszacsatolt neurális hálózat (réteg): különböző célokat szolgáló neurális hálózatok, amelyeket a gyakorlatban sokszor kombinálnak, ekkor az egységekre rétegekként hivatkozunk (pl. konvolúciós réteg).
LSTM: Long Short-Term Memory. Visszacsatolt neuronháló/réteg típus, adatsorok távoli összefüggéseinek modellezésére alkalmas.
GPU: Graphic Processing Unit, grafikus kártya. Eredetileg számítógépes grafika gyors kiszámítására hozták létre. Ma már olyan nagy erőforrásigényű, párhuzamosítható számítások elvégzésére is használják, mint például a mély tanulás.
2016/30