
Szinte hetente jönnek hírek a mesterséges intelligencia (MI) ígéretes alkalmazásairól. Bolgár Bence bioinformatikus a gyógyszerkutatás informatikai oldalával foglalkozik, s ebben a MI működését és lehetőségeit vizsgálja. A BME Méréstechnika és Információs Rendszerek Tanszékének doktorandusza nemrég Junior Prima Díjat kapott, ami eddigi munkáját és annak jövőbeni fontosságát is minősíti. A fiatal szakemberrel az OTKA által is támogatott kutatásairól és azok jelentőségéről beszélgettünk.

– A biológiai vagy az informatikai érdeklődése volt előbb és hogyan találkozott a kettő?
– Édesapám négy éves koromban odaültetett a számítógép elé és elkezdtem programozgatni, majd az öcséimnek írogattam játékprogramokat. Tehát az informatika volt előbb, aztán mégis orvosnak mentem, mert a gimnáziumban nagyon jó biológiatanárom volt, aki ebbe az irányba terelt. A Semmelweisen általános orvostudományt tanultam. Először még én is pipettázgattam a laborban, de nem voltam túl ügyes és inkább az adatelemzés felé fordultam. Az egyetem második felében a Pázmányra is jártam, vendéghallgatóként informatikát és matematikát hallgatni, illetve a BME-n bekapcsolódtam bioinformatikai kutatásokba. Innen jött a gyógyszerkutatás, amiből egy társammal TDK-t is írtam. Elég jól sikerült, mert OTDK első hely lett belőle. Így a PhD-t már a BME-n kezdtem, most főleg gyógyszerkutatással foglalkozom, annak is az informatikai oldalával.
– Milyen céllal kezdett ezen a területen dolgozni?
– Először nem volt vele kifejezett célom azon kívül, hogy új dolgokat ismerjek meg, de most már kezdenek körvonalazódni bennem a dolgok. Az okos kütyük és minden, amit akarva-akaratlanul megosztunk az interneten, hatalmas adatmennyiséget generál. Kevésbé köztudott, hogy az élettudományokban is óriási, egyre növekvő mennyiségű adat áll rendelkezésre. Kézenfekvő, hogy itt van ez a sok adat, használjuk ki. A genetikai adatoktól a mellékhatás-adatokig ma már minden egyre olcsóbban begyűjthető, és nagyon okos MI-algoritmusokkal tudjuk elemezni őket. A mély tanulásnak nevezett módszereket alkalmazzák nagy mennyiségű adatok vagy bonyolult rendszerek elemzéséhez, nemcsak a bioinformatikában, hanem más tudományokban is, mint például a kvantumtérelmélet. Sőt a mindennapi életben is tapasztaljuk egyes alkalmazásait. Ilyen a gépi látás vagy a beszédfelismerés területe. Viszont nem teljesen értjük, hogy ezek a módszerek hogyan képesek olyan teljesítményekre, amikre láthatóan képesek. A cél tehát egyrészt az, hogy megértsük, hogyan működnek, másrészt az, hogy tudományos kutatásban aktívan tudjuk alkalmazni őket.
– Az ön területén hogyan és mire lehet alkalmazni a mesterséges intelligenciát?
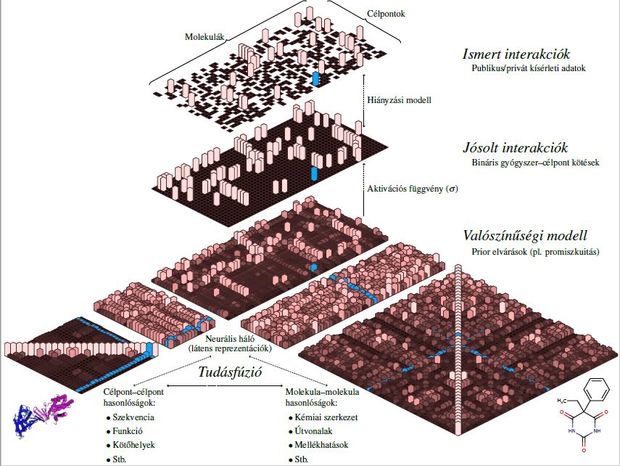
– A gyógyszerek – kissé leegyszerűsítve – úgy hatnak, hogy molekulái elérik a sejtet, és ott elindítanak egy jelátviteli folyamatot, esetleg valami metabolikus útvonalat megváltoztatnak. A sejt valahogy reagál erre és megjelenik egy külsőleg is látható változás. Például lement a vérnyomásom. Annak a megjóslása, hogy egy ilyen molekula milyen célpontokhoz fog bekötni, nagyon fontos, mert ez a gyógyszerfejlesztés nulladik lépése. Általában tehát van egy célpontunk, tudjuk, hogy az milyen élettani folyamatokban játszik kulcsszerepet, és ezt próbáljuk gyógyszerrel támadni a kívánt hatás elérése érdekében. Ezek azonban nagyon költséges kísérletek, de ha már csak annyit el tudunk érni, hogy MI-vel néhány megoldást javaslunk, ami nagy valószínűséggel működni fog, akkor már sokat segítettünk. Persze annak a molekulának, amit találunk, még át kell mennie a szokásos szűrőkön, mire gyógyszer lesz. Én azzal foglalkozom, hogyan lehet ezt a gyógyszer-célpont interakciót megjósolni sok információforrás együttes felhasználásával. Ilyen információ lehet például a molekula kémiai szerkezete, vagy az, hogy ezek a molekulák mennyiben hasonlítanak vagy különböznek egymástól, de későbbi fázisokban például az ismert mellékhatások is fontosak lehetnek. Nagyon sok helyről jöhetnek tehát az információk, így az is kérdés, hogyan tudjuk ezeket együttesen felhasználni. A tudásnak ez a fúziója igazán hasznos és fontos a mi munkánkban. Bizonyos módszereket, például kvantumkémiai szimulációkat, vagy gépi tanulási modellekkel a molekulák fizikai, kémiai tulajdonságainak jóslását már viszonylag régóta alkalmazzák.
– Nagyon leegyszerűsítem a dolgot, ha ezt gyógyszerszimulátorként képzelem el?
– Nem, de gyógyszerszimulációval nem mi foglalkozunk. Amit mi csináltunk, azt úgy lehetne jellemezni, mint a Netflix filmajánló rendszerét. Az egyes felhasználók megnéznek néhány filmet és adnak rá értékelést. Az a feladatunk, hogy a felhasználók eddigi preferenciái alapján új filmeket javasoljunk. Ehhez nagyon sok mindent fel lehet használni, például maguknak a felhasználóknak a hasonlóságait is. Ha az én baráti körömben mindenki könyvmoly, akkor van arra esély, hogy nekem is azok a „könyvmoly” filmek fognak tetszeni, amik nekik. Ezzel analóg módon gondolhatunk arra, hogy a gyógyszermolekulák is értékelnek egyes célpontokat. Az értékelés itt azt jelenti, hogy mekkora affinitással kötnek egy célponthoz. Itt is vannak a molekuláknak és a célpontoknak is hasonlóságai. A modell, amin dolgozom, azt csinálja, hogy teljesen automatizált módon, tehát emberi beavatkozás nélkül a gyógyszereknek és a célpontoknak is készít egy látens reprezentációt. Ezeket használja fel ahhoz, hogy eddig ismeretlen gyógyszer-célpont interakciókról is megmondja, milyen valószínűséggel és milyen affinitással fognak kötni. Itt bejönnek olyan szempontok is, mint az, hogy ami nincs benne az ismert adatainkban, az vajon miért nincs benne? Véletlennek tekinthető, vagy valakinek már megvan, de igyekszik titokban tartani? Tehát statisztikai szempontból nagyon ügyesen kell kezelni ezeket a feltevéseket, a hiányzás típusától is függ, hogyan formalizálja az ember a modellt.
– Ez nemcsak gyorsítja, hanem olcsóbbá is teszi a gyógyszerkészítés első fázisait?
– A sok szempontot fuzionáló rendszerrel a cél még ennél is ambiciózusabb: a gyógyszerkutatás későbbi fázisait is hivatott volna segíteni, több célpont rendszerszemléletű ajánlásával. Sajnos azonban még jelenleg ehhez nincsenek szakmai kiértékelések, így a gyógyszergyárak is inkább kutatási eszközként figyelik ezeket a módszereket.
– Milyen kifutását várja a saját mostani kutatásainak?
– Mindenképpen szeretném, ha meglenne ezeknek a módszereknek a magyarázata. A gép által automatikusan megkonstruált látens reprezentációkhoz valamilyen szemléletes biológiai értelmezést kell találni. A másik ilyen nagyívű célkitűzés, hogy ez a módszer már olyan fejlett lesz, hogy kísérleteket is tud javasolni, sőt azt is tudja, hogy ennek a kísérletnek mi lesz a várható értéke, és az alapján hogyan lehet tovább lépni. Tehát gyakorlatilag a mesterséges intelligencia automatizálja a kutatási folyamatot, részben belépve a gyógyszerkutató helyébe, részben kooperálva, kiegészítve az emberi intuíciót. Azt találták, hogy általában jók ezek a szakértői rendszerek, jó az ember is, de akkor igazán jók, ha együtt dolgoznak.
Érdekesség, hogy a Deep Learning alapját adó matematikai formalizmus az utóbbi 2–3 évben nagyon sok helyen előkerült, egészen távoli területeken, például kvantumtérelméletben is használják. Nagyon úgy tűnik, hogy egy csomó dologról, legyen az kvantumtérelmélet vagy arcfelismerés vagy gyógyszerkutatás, lehet a komputáció, vagy a számítás nyelvén is beszélni. De ezen a nyelven még nem nagyon tudjuk felhasználni, részben azért, mert sok esetben nem értjük, hogy a modellek valójában mit is reprezentálnak. De haladunk afelé, hogy megértsük.
TRUPKA ZOLTÁN
2018/3

